

Haystack یک چارچوب منبع باز آسان برای ساخت خطوط لوله RAG و برنامه های کاربردی مبتنی بر LLM، و پایه و اساس یک پلت فرم مفید SaaS برای مدیریت چرخه زندگی آنها است.
Haystack یک چارچوب منبع باز برای ساخت برنامه های کاربردی بر اساس مدل های زبان بزرگ (LLM) از جمله برنامه های کاربردی نسل افزوده-بازیابی (RAG)، سیستم های جستجوی هوشمند برای مجموعه های اسناد بزرگ و موارد دیگر. Haystack در حال حاضر منحصراً در Python پیاده سازی شده است.
Haystack همچنین پایه و اساس ابر عمیق است. deepset حامی اصلی Haystack است و چندین کارمند deepset در پروژه Haystack مشارکت دارند.
یکپارچهسازی با Haystack شامل مدلهایی است که روی پلتفرمهایی مانند Hugging Face، OpenAI و Cohere میزبانی میشوند. مدلهای مستقر در پلتفرمهایی مانند Amazon SageMaker، Microsoft Azure AI و Google Vertex AI. و ذخیرههای برداری و اسناد، مانند Elasticsearch، OpenSearch، Pinecone و Qdrant. علاوه بر این، جامعه Haystack ادغام هایی را برای ابزارهایی که ارزیابی مدل، نظارت، و دریافت داده ها را انجام می دهند، ارائه کرده است.
موارد استفاده برای Haystack شامل RAG، رباتهای چت، عاملها، پاسخگویی به سؤالات چندوجهی و استخراج اطلاعات از اسناد است. Haystack عملکردی را برای دامنه کامل پروژههای LLM، مانند یکپارچهسازی منبع داده، تمیز کردن و پیشپردازش دادهها، مدلها، گزارشگیری، و ابزار دقیق فراهم میکند.
قطعات و خطوط لوله Haystack به شما کمک می کند تا برنامه ها را به راحتی جمع آوری کنید. در حالی که Haystack دارای بسیاری از اجزای از پیش ساخته شده است، افزودن یک جزء سفارشی به سادگی نوشتن یک کلاس پایتون است. خطوط لوله اجزا را به نمودارها یا نمودارهای چندگانه متصل می کند (نیازی نیست نمودارها غیر چرخه ای باشند) و Haystack خطوط لوله نمونه زیادی را برای موارد استفاده معمول ارائه می دهد. Deepset Studio، محصول جدیدی که به توسعه دهندگان هوش مصنوعی اجازه می دهد خطوط لوله اختصاصی هوش مصنوعی را طراحی و تجسم کنند، در ۱۲ آگوست معرفی شد.
Haystack به همراه LlamaIndex، LangChain ، و هسته معنایی .
هیستاک چیست؟
بهعنوان یک چارچوب متنباز برای ساخت برنامههای LLM، Haystack سعی میکند به جای انجام همه کارها، کارهای مهم را به درستی انجام دهد. Haystack به اندازه LangChain یکپارچه سازی شخص اول ندارد، اما دارای ۳۴ ادغام فعلی است و به طور کامل از آن پشتیبانی می کند. دارد. Haystack همچنین ۲۸ ادغام با مشارکت جامعه را ارائه می دهد تا چارچوب را به فروشگاه های داده ها و اسناد کمتر محبوب، مدل ها، ابزارها و API ها پیوند دهد. من قبل از بحث در مورد معماری چارچوب اصلی به ادغام ها اشاره می کنم (به “مفاهیم Haystack” در زیر مراجعه کنید) زیرا ادغام ها در واقع به تلاش توسعه بیشتری نسبت به قابلیت های ارکستراسیون اصلی نیاز دارند.
علاوه بر ارزشگذاری درست انجام کارها بر انجام همه کارها، Haystack سعی میکند صریح باشد تا ضمنی. این ممکن است به معنای نوشتن کد بیشتر در اولین باری باشد که یک خط لوله ایجاد می کنید، اما در ازای آن تلاش اولیه اضافی، اشکال زدایی، به روز رسانی و حفظ خط لوله خود را بسیار آسان تر خواهید یافت. برای مقابله با سختی نوشتن کدهای صریح زیاد، می توانید نمودارهای خط لوله خود را به صورت بصری با دیپ ست استودیو ایجاد کنید که در زیر مورد بحث قرار گرفته است.
چهار هدف اصلی طراحی Haystack عبارتند از: فنآور بودن، صریح بودن (همانطور که قبلاً بحث کردیم)، انعطافپذیر بودن و توسعهپذیر بودن. مخزن Haystack README این موارد را به شرح زیر توصیف می کند:
- تکنولوژی آگنوستیک: به کاربران این امکان را میدهد که تصمیم بگیرند چه فروشنده یا فناوری را میخواهند و تعویض هر جزء را برای دیگری آسان میکند. Haystack به شما امکان می دهد از مدل های موجود از OpenAI، Cohere، و Hugging Face و همچنین مدل های محلی یا مدل های میزبانی شده در Azure، Bedrock و SageMaker استفاده و مقایسه کنید.
- صریح: شفاف سازی کنید که چگونه قسمتهای متحرک مختلف میتوانند با یکدیگر “صحبت کنند” تا راحتتر با پشته فناوری و جعبه استفاده شما جا بیفتند.
- انعطاف پذیر: Haystack همه ابزارها را در یک مکان فراهم می کند: دسترسی به پایگاه داده، تبدیل فایل، تمیز کردن، تقسیم، آموزش، ارزیابی، استنتاج و موارد دیگر. و هر زمان که رفتار سفارشی مطلوب باشد، ایجاد اجزای سفارشی آسان است.
- توسعه پذیر: راهی یکنواخت و آسان برای جامعه و اشخاص ثالث برای ایجاد اجزای خود و ایجاد یک اکوسیستم باز در اطراف Haystack فراهم کنید.
علاوه بر ساخت برنامههای نسل افزوده بازیابی با استفاده از پایگاه داده برداری، Haystack میتواند برای گسترش برنامههای RAG برای ایجاد عاملها (آنچه مایکروسافت آن را copilot مینامد) و همچنین برای پاسخگویی به سؤال، استخراج اطلاعات، جستجوی معنایی و ساختن استفاده شود. برنامه هایی که پرس و جوهای پیچیده را حل می کنند. برنامه های Haystack می توانند از مدل های خارج از قفسه و مدل های سفارشی تنظیم شده استفاده کنند. اگر از مدلهای چند وجهی استفاده میکنید، Haystack همچنین میتواند برای انجام تولید تصویر، شرح تصاویر و رونویسی صدا نیز استفاده شود.
مفاهیم انبار کاه
اساسا، Haystack راهی برای ایجاد خطوط لوله RAG سفارشی با LLM ها و فروشگاه های برداری را در اختیار شما قرار می دهد. این در اجزاء، انبارهای اسناد، کلاس های داده و خطوط لوله سازماندهی شده است. توجه داشته باشید که Haystack در مورد جستجوی برداری و تعبیه برداری خود بی اعتنا است.
اجزای انبار کاه
مؤلفههای خط لوله در Haystack کلاسهای پایتون با متدهایی هستند که میتوانید مستقیماً آنها را فراخوانی کنید. آنها طیف گسترده ای از عملکردها را اجرا می کنند، از رونویسی صوتی تا نویسندگان اسناد. اگر قابلیتی وجود دارد که باید برای برنامه خود اضافه کنید، می توانید یک کلاس جزء سفارشی جدید با استفاده از Haystack Component API بنویسید. اگر یک API یا پایگاه داده شخص ثالث وجود داشته باشد که کارهای مورد نیاز شما را انجام دهد، Component API اتصال به خطوط لوله شما را آسان می کند و Haystack قبل از اجرای خط لوله، اتصالات بین اجزا را تأیید می کند.
ژنراتورها اجزایی هستند که مسئول تولید پاسخهای متنی پس از ارسال درخواست به آنها هستند. ژنراتورها مختص LLM هستند که با آن تماس می گیرند و دو نوع از آنها وجود دارد: چت و غیر چت. مولدهای چت برای مکالمات طراحی شدهاند و لیستی از پیامها را برای متن انتظار دارند. مولدهای غیر چت برای تولید متن ساده، به عنوان مثال، خلاصه سازی و ترجمه طراحی شده اند.
بازیابها در Haystack اسنادی را از یک ذخیرهسازی اسناد استخراج میکنند که ممکن است مربوط به درخواست کاربر باشد، و آن زمینه را به مؤلفه بعدی در خط لوله منتقل میکنند، که در سادهترین حالت یک مولد است. رتریورها مختص محل ذخیره اسنادی هستند که استفاده می کنند.
فروشگاه های اسناد Haystack
ذخیرههای اسناد، اشیای Haystack هستند که اسناد شما را برای بازیابی بعدی ذخیره میکنند. آنها مختص پایگاه داده های برداری هستند، به جز InMemoryDocumentStore، که ذخیره سازی اسناد، جاسازی برداری و بازیابی را به تنهایی پیاده سازی می کند. مؤلفه InMemoryDocumentStore برای توسعه و آزمایش است، اما زودگذر است و در مقیاس تولید نیست.
اجزای ذخیره اسناد از روشهایی مانند write_documents() و bm25_retrieval() پشتیبانی میکنند. همچنین میتوانید از یک مؤلفه DocumentWriter برای افزودن فهرستی از اسناد به ذخیرهسازی اسناد مورد نظر خود استفاده کنید. اجزای DocumentWriter معمولاً در خط لوله نمایه سازی استفاده می شوند.
کلاس های داده انبار کاه
کلاسهای داده به اجزای Haystack کمک میکنند تا با یکدیگر ارتباط برقرار کنند و به دادهها اجازه میدهند در خطوط لوله جریان پیدا کنند. کلاس های داده Haystack شامل ByteStream است. Answer و زیر کلاسهای آن ExtractedAnswer، ExtractedTableAnswer و GeneratedAnswer؛ پیام چت؛ سند؛ و StreamingChunk. کلاس Document می تواند شامل متن، قاب داده، حباب، ابرداده، امتیاز و بردار جاسازی باشد. StreamingChunk یک پاسخ LLM نیمه جریانی را نشان می دهد.
خطوط انبار کاه
خطوط لوله اجزاء، ذخیره اسناد و ادغام ها را در سیستم های سفارشی ترکیب می کند. آنها می توانند به سادگی یک خط لوله RAG اصلی باشند که از یک پایگاه داده برداری برای داده های مرتبط پرس و جو می کند، از آن داده ها برای درخواست LLM استفاده می کند و پاسخ LLM را برمی گرداند، یا می توانند نمودارهای پیچیده یا چند نموداری دلخواه باشند که ممکن است شامل جریان های همزمان باشد. اجزای مستقل و حلقه ها.
ابر عمیق چیست؟
deepset Cloud یک پلتفرم SaaS برای ساخت برنامه های LLM و مدیریت آنها در کل چرخه عمر، از نمونه سازی تا تولید است. به طور خلاصه، Haystack در فضای ابری با رابط کاربری گرافیکی خوب برای توسعه و آزمایش، و رابط REST برای تولید است.
با Deepset Cloud میتوانید دادههای خود را از قبل پردازش کنید و آنها را برای جستجو، طراحی و ارزیابی خطوط لوله آماده کنید، و آزمایشهایی را برای جمعآوری معیارهای عملکرد خط لوله خود و تکرار انجام دهید. همچنین می توانید خطوط لوله خود را برای نمایش و آزمایش با دیگران به اشتراک بگذارید. Deepset Cloud شامل Prompt Studio برای مهندسی سریع، مقیاسبندی خودکار خطوط لوله مستقر شده، و Deepset Studio برای طراحی خطوط لوله بصری است. خطوط لوله همچنین می توانند از یک الگو، مشخص شده در YAML، یا با استفاده از API در پایتون کدگذاری شوند.
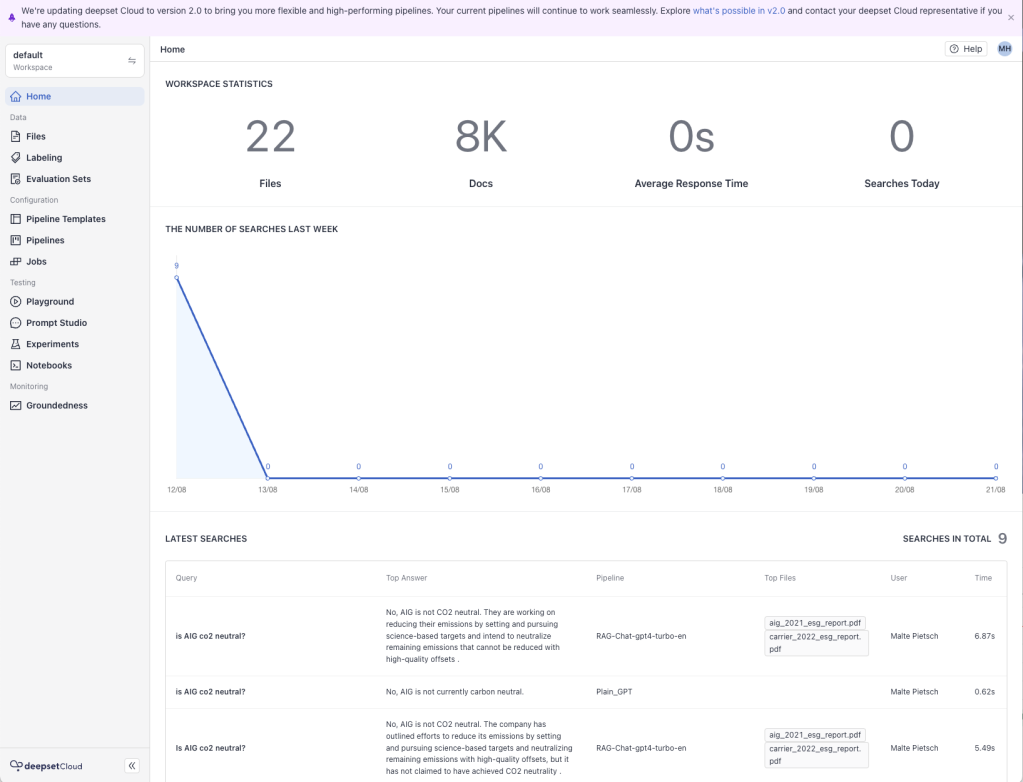
Cloud Home را عمیق کنید. به منوی عملکرد در سمت چپ و لیست آخرین جستجوها در پایین توجه کنید.
IDG
Deepset Studio
deepset Studio یک طراح خط لوله تصویری جدید است که در حال حاضر در نسخه بتا کنترل شده است. و به صورت رایگان در دسترس است. من آن را در دیپست Cloud امتحان کردم، اما به عنوان یک محصول مستقل نیز در دسترس است.
deepset Studio به شما امکان میدهد از یک رابط کاربری با کشیدن و رها کردن برای دسترسی به کتابخانه Haystack از اجزا و ادغامها استفاده کنید. میتوانید تمام اجزا و ویژگیهای آنها را ببینید، آنها را در خطوط لوله ترکیب کنید، معماریهای آنها را تجسم کنید، بین کدهای ۱:۱ و نماهای بصری جابجا شوید، و تنظیمات نهایی را بهعنوان یک فایل YAML برای استفاده در محیطهای مختلف صادر کنید.
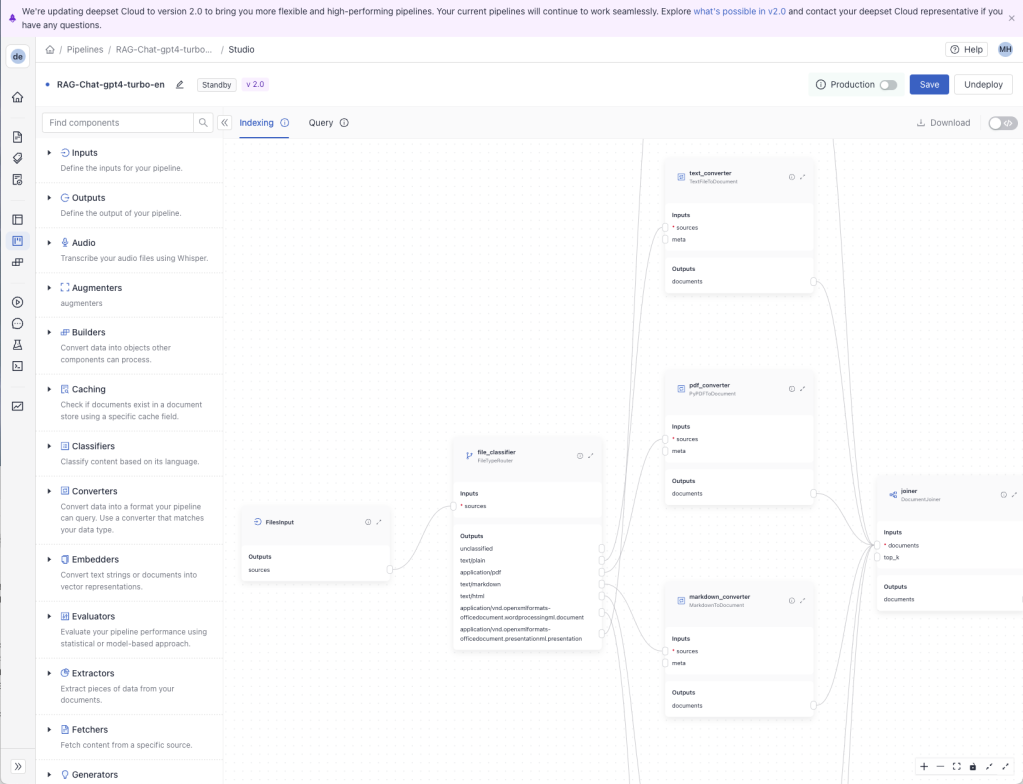
Deepset Studio در حال اجرا در Deepset Cloud. این خط لوله یک پیادهسازی نسبتاً ساده RAG است که نیمی از فرمتهای فایل را برای اسناد ورودی مدیریت میکند و (خارج از صفحه سمت راست) امکان چت با gpt4-turbo را فراهم میکند.
IDG

استفاده از الگوهای خط لوله راهی سریع برای شروع با Haystack در دیپست Cloud است. هنگامی که یک خط لوله از یک الگو ایجاد کردید، می توانید آن را برای برنامه خود ویرایش کنید.
IDG
شروع به کار با Haystack
همانطور که در مستندات “شروع به کار” توضیح داده شده است، می توانید Haystack را با:
نصب کنید
pip install haystack-ai
سپس باید یک متغیر محیطی Secret یا OPENAI_API_KEY Haystack تنظیم کنید. به مقدار کلید OpenAI شما. اگر هنوز کلید OpenAI ندارید، میتوانید آن را از پلتفرم OpenAI دریافت کنید. ممکن است شما را ملزم به ثبت نام با OpenAI و ارائه یک کارت اعتباری کند. ثبت نام برای دسترسی ChatGPT را با ثبت نام برای دسترسی OpenAI API اشتباه نگیرید، زیرا این دو از هم جدا هستند. استفاده از API نسبتاً ارزان است.
کد پایتون را برای برنامه بسیار ساده شروع RAG از مستندات Haystack کپی کنید و آن را در یک ویرایشگر قرار دهید. من از کد ویژوال استودیو استفاده کردم.
همانطور که ارائه شد، کد پایتون در خط ۳۱ یک Secret Haystack را انتظار دارد. اگر به جای آن یک متغیر محیطی را انتخاب کرده اید، ساده ترین راه برای تغییر خط ۳۱ این است که بدنه فراخوانی تابع را حذف کنید و بخوانید:
llm = OpenAIGenerator()
این باعث می شود کلاس Secret از اولین متغیر محیطی که پیدا کرده مقداردهی اولیه شود. اگر میخواهید دقیقتر باشید، میتوانید از فرم api_key=Secret.from_env("OPENAI_API_KEY") در تماس OpenAIGenerator() استفاده کنید.
برنامه را اجرا کنید و باید خروجی را در ترمینال ببینید:
[«ژان در پاریس زندگی میکند.»]
یک توضیح (یا دستور العمل) پاپ آپ برای کد وجود دارد که می توانید با کلیک بر روی کادر زیر کد با عنوان “۲.۰ RAG Pipeline” از مستندات به آن دسترسی پیدا کنید. همچنین می توانید با اشکال زدایی کد و ردیابی هر فراخوانی تابع Haystack چیزهای زیادی یاد بگیرید تا ببینید چگونه کار می کند. در نهایت، میتوانید پیوند را دنبال کنید تا یاد بگیرید چگونه دادههای سفارشی خود را با استفاده از فروشگاههای اسناد اضافه کنید.. p>
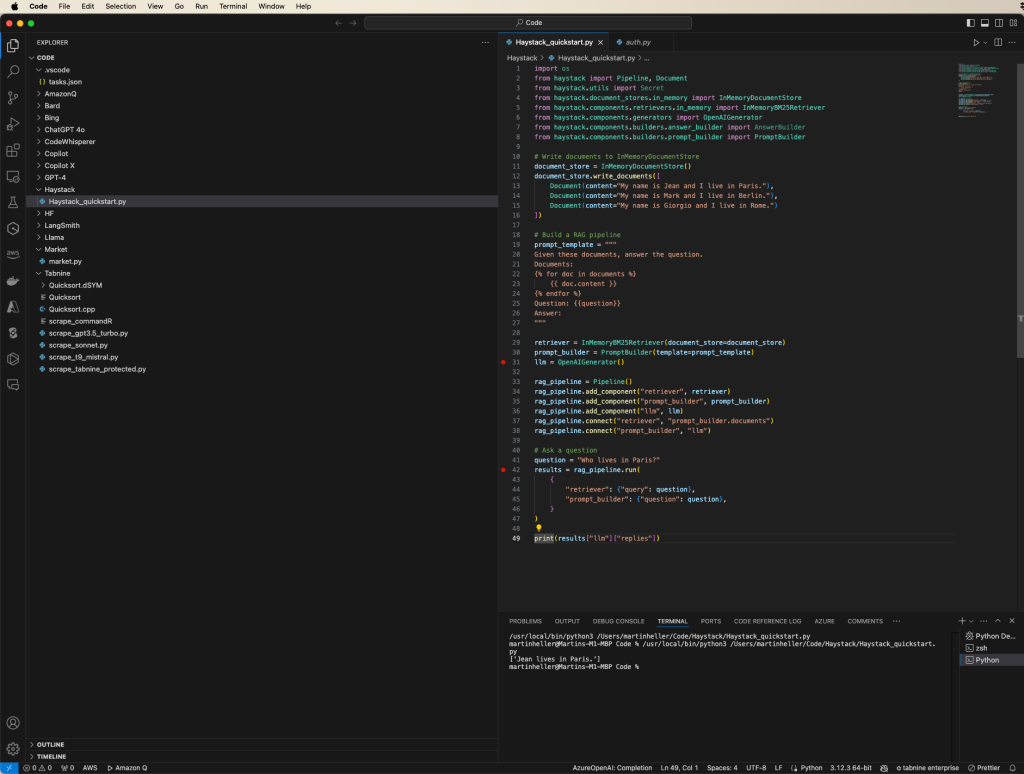
کد شروع سریع پایتون در حال اجرا در کد ویژوال استودیو. من قبلاً یک متغیر محیطی OPENAI_API_KEY را به مقدار کلید مخفی OpenAI خود صادر کردم. من همچنین خط ۳۱ را همانطور که در متن بالا توضیح داده شد تغییر دادم تا از متغیر محیط استفاده کنم.
IDG
منابع یادگیری Haystack
میتوانید از اسناد، مرجع API، آموزش ها و مقدمات، < یک href="https://github.com/deepset-ai/haystack-cookbook">کتاب آشپزی، پستهای وبلاگ a>، و مخزن کد منبع. میتوانید درباره Haystack در Discord آن بحث کنید. می توانید برای یک دوره یک ساعته ساخت برنامه های هوش مصنوعی با Haystack ثبت نام کنید. به صورت رایگان در DeepLearning.AI، توسط Tuana Çelik، مدیر روابط توسعهدهنده در Haystack توسط deepset.
به طور کلی، Haystack یک چارچوب منبع باز بسیار خوب برای ساخت برنامه های LLM است، و دیپ ست کلود یک پلت فرم SaaS بسیار خوب برای ساخت برنامه های LLM و مدیریت آنها در کل چرخه حیات است. Deepset Studio یک طراح خط لوله بصری خوب است. زمانی که بتواند نمودارهای خط لوله را به کد پایتون تبدیل کند، بهتر خواهد بود، اما می توان آنها را در YAML و همچنین نمودارها مشاهده کرد.
Haystack با LlamaIndex، LangChain و Semantic Kernel رقابت می کند. صادقانه بگویم، هر چهار فریم ورک برای اکثر موارد استفاده از برنامه های LLM کار می کنند. از آنجایی که همه آنها منبع باز هستند، می توانید امتحان کنید و از همه آنها به صورت رایگان استفاده کنید. ابزارهای اشکال زدایی آنها متفاوت است، پشتیبانی از زبان برنامه نویسی آنها متفاوت است، و روش هایی که آنها نسخه های ابری را پیاده سازی کرده اند نیز متفاوت است. من به شما توصیه می کنم که هر کدام را برای یک یا سه روز با یک مورد استفاده واضح اما ساده از خودتان به عنوان هدف امتحان کنید و ببینید کدام یک برای شما بهتر است.
خط پایین
Haystack یک چارچوب منبع باز بسیار خوب برای ساخت برنامه های LLM است و دیپ ست کلود یک پلت فرم SaaS بسیار خوب برای ساخت برنامه های LLM و مدیریت آنها در کل چرخه زندگی است. Deepset Studio یک طراح خط لوله بصری خوب است. زمانی که بتواند نمودارهای خط لوله را به کد پایتون تبدیل کند، بهتر خواهد بود.
مزایا
- چارچوب منبع باز برای ساخت برنامه های LLM آماده تولید
- در پایتون پیادهسازی شد
- پیاده سازی ابر SaaS خوب
- مجموعه خوبی از ادغام با مدلها، جستجوی برداری، و ابزار
- از نظارت با Chainlit و Traceloop پشتیبانی میکند
معایب
- در زبان های برنامه نویسی غیر از پایتون اجرا نشده است
- deepset Studio هنوز در نسخه بتا کنترل شده است به جز در دیپ ست Cloud
هزینه
Haystack 2.0: رایگان. deepset Cloud: تماس با deepset.
سکوها
Python 3.8 یا بالاتر.




پست های مرتبط
بررسی Haystack: یک برنامه ساز انعطاف پذیر LLM
بررسی Haystack: یک برنامه ساز انعطاف پذیر LLM
بررسی Haystack: یک برنامه ساز انعطاف پذیر LLM