

برخی از کاربران توییتر که به Mastodon مهاجرت میکنند، نمیتوانند جستجوی تمام متنی را برای خود انجام دهند. در اینجا نحوه جستجوی پست های خود با استفاده از R و بسته rtoot آورده شده است.
- تنظیم جستجوی متن کامل
- دادههای خود را بکشید و ذخیره کنید
- یک جدول قابل جستجو با نتایج خود ایجاد کنید
- نحوه دریافت پستهای جدید Mastodon
- نحوه خواندن آرشیو Mastodon دانلود شده
چه به طور کامل از توییتر به ماستودون مهاجرت کرده باشید، چه فقط “فدیورس” را امتحان کرده باشید، یا یک کاربر قدیمی Mastodon بوده باشید، ممکن است نتوانید در متن کامل “toots” (همچنین به عنوان شناخته شده است) جستجو کنید. نوشته ها). در Mastodon، هشتگ ها قابل جستجو هستند، اما سایر متن های غیر هشتگ قابل جستجو نیستند. در دسترس نبودن جستجوی متن کامل به کاربران اجازه می دهد تا کنترل کنند که چه مقدار از محتوای آنها توسط غریبه ها به راحتی قابل کشف است. اما اگر بخواهید بتوانید پست های خود را جستجو کنید چه؟
بعضی از نمونههای Mastodon به کاربران اجازه میدهند تا جستجوی تمام متنی را برای خود انجام دهند، اما برخی دیگر بسته به سرپرست این امکان را ندارند. خوشبختانه، به لطف R و بسته rtoot که توسط David Schoch توسعه یافته است، جستجوی متن کامل پست های Mastodon خود آسان است. این همان چیزی است که این مقاله در مورد آن است.
تنظیم جستجوی متن کامل
ابتدا، بسته rtoot را در صورتی که قبلاً روی سیستم شما نیست با install.packages("rtoot") نصب کنید. من همچنین از بسته های dplyr و DT استفاده خواهم کرد. هر سه را می توان با دستور زیر بارگذاری کرد:
# install.packages("rtoot") # if needed
library(rtoot)
library(dplyr)
library(DT)
در مرحله بعد، به شناسه Mastodon خود نیاز دارید که با نام کاربری و نمونه شما یکسان نیست. بسته rtoot شامل راهی برای جستجوی حسابها در سراسر جهان است. این ابزار مفیدی است اگر میخواهید ببینید آیا کسی در جایی در Mastodon حساب دارد یا خیر. اما از آنجایی که شناسه های حساب را نیز برمی گرداند، می توانید از آن برای یافتن شناسه خود نیز استفاده کنید.
برای جستجوی شناسه خودم، از:
استفاده میکنم
accounts <- search_accounts("smach@fosstodon.org")
این کار احتمالا فقط یک دیتافریم با یک نتیجه را باز می گرداند. اگر فقط یک نام کاربری را جستجو کنید و هیچ نمونه ای مانند search_accounts("posit") را جستجو کنید تا ببینید آیا Posit (RStudio سابق) در Mastodon فعال است یا خیر، ممکن است نتایج بیشتری وجود داشته باشد.
جستجوی من فقط یک نتیجه داشت، بنابراین شناسه من اولین (و همچنین تنها) مورد در ستون id است:
my_id <- accounts$id[1]
اکنون میتوانم پستهایم را با عملکرد get_account_statuses() rtoot بازیابی کنم.
داده های خود را بکشید و ذخیره کنید
پیشفرض حداقل فعلاً ۲۰ نتیجه را برمیگرداند، اگرچه اگر آن را به صورت دستی با آرگومان limit تنظیم کنید، به نظر میرسد این محدودیت بسیار بیشتر است. با این حال، در مورد استفاده از این تنظیمات مهربان باشید، زیرا اکثر نمونه های Mastodon توسط داوطلبانی اداره می شوند که اخیراً هزینه های میزبانی بسیار افزایش یافته است.
اولین باری که سعی میکنید دادههای خود را جمعآوری کنید، از شما خواسته میشود که احراز هویت کنید. من برای دریافت ۵۰ پست اخیر خود، موارد زیر را اجرا کردم (به استفاده از verbose = TRUE برای دیدن هر پیامی که ممکن است برگردانده شود توجه کنید):
smach_statuses <- get_account_statuses(my_id, limit = 50, verbose = TRUE)
بعد، از من پرسیده شد که آیا میخواهم احراز هویت کنم. پس از انتخاب بله، عبارت زیر را دریافت کردم:
On which instance do you want to authenticate (e.g., "mastodon.social")?
مهم!
اگرچه مثال "mastodon.social" شامل علامت نقل قول است، پاسخی که برای من کارآمد بود، نمونه من بدون علامت نقل قول بود. یعنی فقط fosstodon.org و نه "fosstodon.org".
بعد، از من پرسیده شد:
What type of token do you want?
۱: public
۲: user
از آنجایی که من میخواهم این اختیار را داشته باشم که همه فعالیتها را در حساب خود ببینم، کاربر را انتخاب کردم. سپس بسته یک نشانه احراز هویت برای من ذخیره کرد و من میتوانم get_account_statuses() را اجرا کنم.
قاب داده به دست آمده – که در واقع یک tibble بود، نوع خاصی از قاب داده که توسط بستههای tidyverse استفاده میشود – شامل ۲۹ ستون است. تعدادی از ستونهای فهرست مانند حساب و media_tachments با نتایج غیراتمی هستند، به این معنی که نتایج در قالب دو بعدی دقیق نیستند.
پیشنهاد میکنم قبل از ادامه این کار، این نتیجه را ذخیره کنید تا درصورتیکه مشکلی در جلسه R یا کد شما پیش بیاید، نیازی به پینگ مجدد سرور نداشته باشید. من معمولاً از saveRDS استفاده می کنم، مانند:
saveRDS(smach_statuses, "smach_statuses.Rds")
تلاش برای ذخیره نتایج بهعنوان فایل پارکت به دلیل ستونهای فهرست پیچیده کار نمیکند. استفاده از بسته vroom برای ذخیره به عنوان یک فایل CSV کار می کند و شامل متن کامل ستون های لیست است. با این حال، ترجیح میدهم بهعنوان یک فایل بومی Rds یا .Rdata ذخیره کنم.
یک جدول قابل جستجو با نتایج خود ایجاد کنید
اگر تنها چیزی که می خواهید یک جدول قابل جستجو برای جستجوی متن کامل است، فقط به تعدادی از آن ۲۹ ستون نیاز دارید. قطعاً created_at، url، spoiler_text (اگر از اخطارهای محتوا استفاده میکنید و میخواهید آنها را در جدول خود داشته باشید)، و محتوا را میخواهید. اگر نمیتوانید معیارهای تعامل را در پستهای خود مشاهده کنید، reblogs_count، favourites_count و replies_count را اضافه کنید.
در زیر کدی است که برای ایجاد دادهها برای جدول قابل جستجو برای مشاهده خودم استفاده میکنم. من یک ستون URL برای ایجاد یک >> قابل کلیک با URL پست اضافه کردم که سپس آن را به انتهای محتوای هر پست اضافه می کنم. این باعث میشود که به راحتی به نسخه اصلی کلیک کنید:
tabledata <- smach_statuses |>
filter(content != "") |>
# filter(visibility == "public") |> # If you want to make this public somewhere. Default includes direct messages.
mutate(
url = paste0("<a target = 'blank' href = '", uri,"'><strong> >></strong></a>"),
content = paste(content, url),
created_at := as.character(as.POSIXct(created_at, format = "%Y-%m-%d %H:%M UTC"))
) |>
select(CreatedAt = created_at, Post = content, Replies = replies_count, Favorites = favourites_count, Boosts = reblogs_count)
اگر من این جدول را بهصورت عمومی به اشتراک میگذاشتم، مطمئن میشدم که filter(visibility == "public") را حذف میکردم تا فقط پستهای عمومی من در دسترس باشد. دادههای بازگردانده شده توسط get_account_statuses() برای حساب شخصی شما شامل پستهایی است که فهرست نشده (در دسترس هر کسی که آنها را پیدا کند اما به طور پیشفرض در جدول زمانی عمومی وجود ندارد) و همچنین پستهایی که فقط برای دنبالکنندگان یا مستقیم تنظیم شدهاند. پیام ها.
روش های زیادی برای تبدیل این داده ها به یک جدول قابل جستجو وجود دارد. یک راه با بسته DT است. کد زیر یک جدول HTML تعاملی با کادرهای فیلتر جستجو ایجاد می کند که می تواند از عبارات منظم استفاده کند. (برای اطلاعات بیشتر در مورد استفاده از DT به انجام بیشتر با R: جداول HTML تعاملی سریع مراجعه کنید.)
DT::datatable(tabledata, filter = 'top', escape = FALSE, rownames = FALSE,
options = list(
search = list(regex = TRUE, caseInsensitive = TRUE),
pageLength = 20,
lengthMenu = c(25, 50, 100),
autowidth = TRUE,
columnDefs = list(list(width = '80%', targets = list(2)))
))
در اینجا تصویری از جدول به دست آمده است:
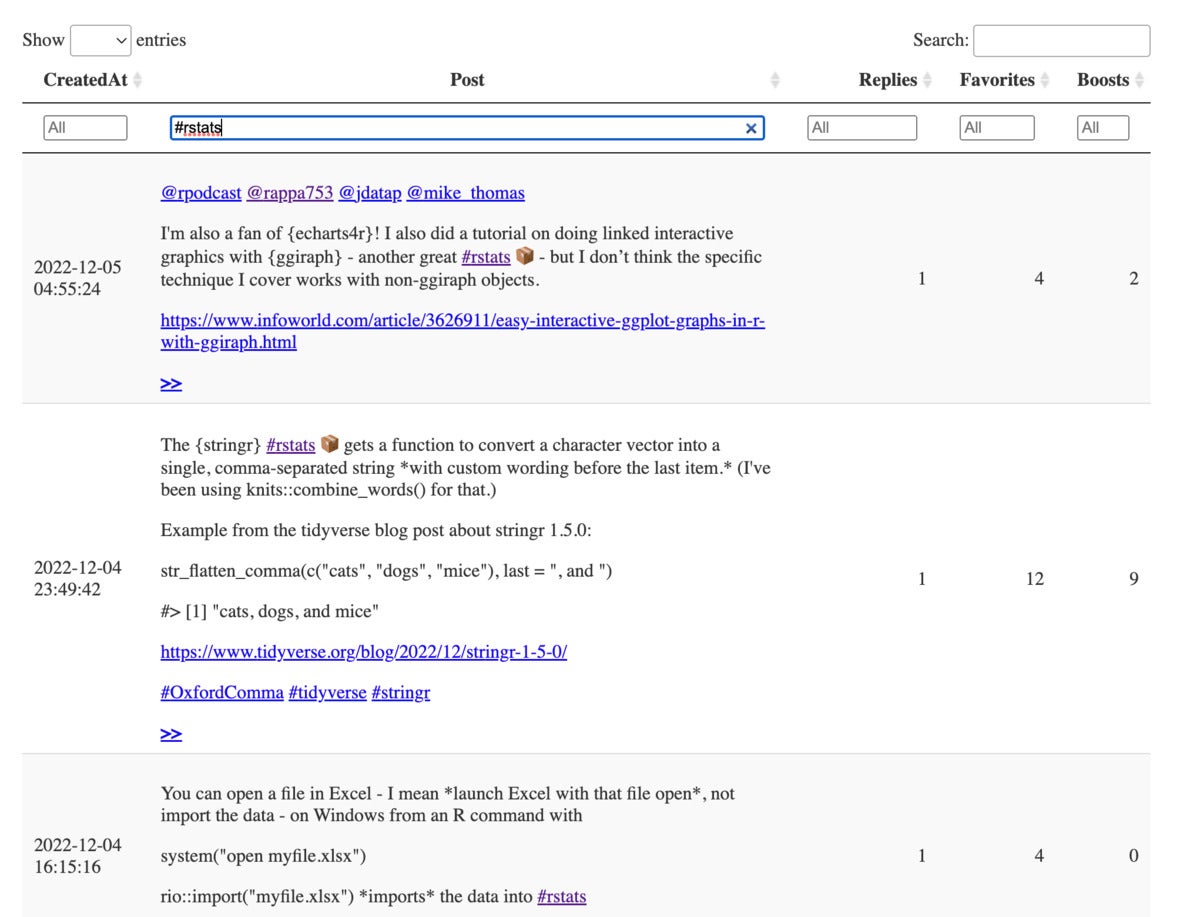
یک جدول تعاملی از پست های Mastodon من. این جدول با بسته DT R با استفاده از rtoot ایجاد شده است.
چگونه پست های جدید Mastodon را وارد کنیم
بهروزرسانی دادههای خود برای ارسال پستهای جدید آسان است، زیرا تابع get_account_statuses() شامل آرگومان since_id است. برای شروع، حداکثر شناسه را از دادههای موجود پیدا کنید:
max_id <- max(smach_statuses$id)
بعد، به دنبال بهروزرسانی با همه پستها از زمان max_id:
new_statuses <- get_account_statuses(my_id, since_id = max_id,
limit = 10, verbose = TRUE)
all_statuses <- bind_rows(new_statuses, smach_statuses)
اگر میخواهید معیارهای تعامل بهروزرسانی شده برای برخی از پستهای اخیر را در دادههای موجود مشاهده کنید، پیشنهاد میکنم به جای استفاده از since_id، ۱۰ یا ۲۰ پست کلی آخر را دریافت کنید. سپس می توانید آن را با داده های موجود ترکیب کنید و با نگه داشتن اولین مورد، آن را حذف کنید. در اینجا یک راه برای انجام این کار وجود دارد:
new_statuses <- get_account_statuses(my_id, limit = 25, verbose = TRUE)
all_statuses <- bind_rows(new_statuses, smach_statuses) |>
distinct(id, .keep_all = TRUE)
نحوه خواندن آرشیو Mastodon دانلود شده
راه دیگری برای دریافت همه پستهای شما وجود دارد، که به ویژه در صورتی مفید است که مدتی در Mastodon بودهاید و در آن مدت فعالیت زیادی داشته باشید. می توانید بایگانی Mastodon خود را از وب سایت دانلود کنید.
در رابط وب Mastodon، روی نماد چرخدنده کوچک در بالای ستون سمت چپ برای تنظیمات کلیک کنید، سپس وارد کردن و صادر کردن > صادرات داده را کلیک کنید. باید گزینه ای برای دانلود آرشیو پست ها و رسانه های خود مشاهده کنید. با این حال، فقط میتوانید هر هفت روز یک بار درخواست بایگانی کنید، و این شامل هیچ معیار تعامل نخواهد بود.
هنگامی که بایگانی را دانلود کردید، می توانید آن را به صورت دستی باز کنید یا همانطور که ترجیح می دهم از بسته بایگانی (موجود در CRAN) برای استخراج فایل ها استفاده کنید. همچنین بستههای jsonlite، stringr، و tidyr را قبل از استخراج فایلها از بایگانی بارگیری میکنم:
library(archive)
library(jsonlite)
library(stringr)
library(tidyr)
archive_extract("name-of-your-archive-file.tar.gz")
بعد، باید به orderItems outbox.json نگاه کنید. در اینجا نحوه وارد کردن آن به R:
آمده است
my_outbox <- fromJSON("outbox.json")[["orderedItems"]]
my_posts <- my_outbox |>
unnest_wider(object, names_sep = "_")
از آنجا، من یک مجموعه داده برای یک جدول قابل جستجو مشابه آنچه در نتایج rtoot ایجاد شده بود، ایجاد کردم. این بایگانی شامل تمام فعالیتها، مانند انتخاب پست دیگر به دلخواه است، به همین دلیل است که من هم برای نوع ایجاد و هم برای اطمینان از اینکه object_content دارای مقدار است فیلتر میکنم. مانند قبل، من یک URL >> قابل کلیک را به محتوای پست اضافه می کنم و نحوه نمایش تاریخ ها را تغییر می دهم:
search_table_data <- my_posts |>
filter(type == "Create") |>
filter(!is.na(object_content)) |>
mutate(
url = paste0("<a target = 'blank' href = '", object_url,"'><strong> >></strong></a>")
) |>
rename(CreatedAt = published, Post = object_content) |>
mutate(CreatedAt = str_replace_all(CreatedAt, "T", " "),
CreatedAt = str_replace_all(CreatedAt, "Z", " "),
Post = str_replace(Post, "<\\/p>$", " "),
Post = paste0(Post, " ", url, "</p>")
) |>
select(CreatedAt, Post) |>
arrange(desc(CreatedAt))
سپس، ایجاد یک جدول قابل جستجو با DT یک تابع ساده دیگر است:
datatable(search_table_data, rownames = FALSE, escape = FALSE,
filter = 'top', options = list(search = list(regex = TRUE)))
این برای استفاده شخصی شما مفید است، اما من از نتایج بایگانی برای اشتراکگذاری عمومی استفاده نمیکنم، زیرا کمتر مشخص است که کدام یک از این پیامها ممکن است پیامهای خصوصی باشند (شما باید مقداری فیلتر در انجام دهید تا ستون ).
اگر درباره این مقاله سؤال یا نظری دارید، میتوانید من را در Mastodon در smach پیدا کنید. @fosstodon.org و همچنین گاهی اوقات هنوز در توییتر در @sharon000 ( اگرچه مطمئن نیستم برای چه مدت دیگر). من همچنین در LinkedIn هستم.
برای نکات R بیشتر، به صفحه بیشتر با R انجام دهید در InfoWorld بروید.




پست های مرتبط
جستجوی متن کامل پست های Mastodon خود را با R
جستجوی متن کامل پست های Mastodon خود را با R
جستجوی متن کامل پست های Mastodon خود را با R